Code
ggplot(mpg, aes(x = hwy, y = cty, color = cyl)) +
geom_point(alpha = 0.5, size = 2) +
scale_color_viridis_c() +
theme_minimal()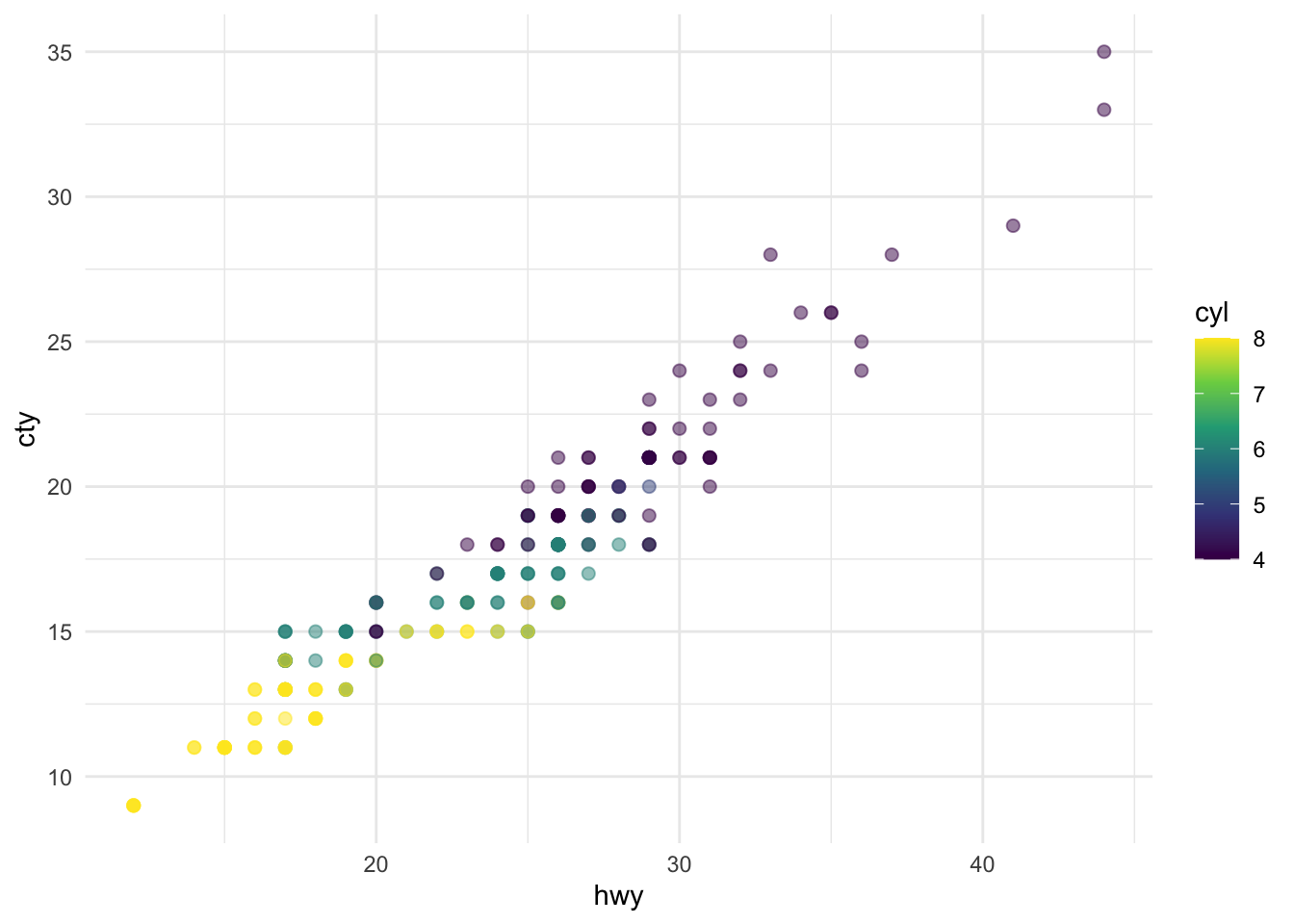
This is a test of quarto
Recreating examples from the quarto website
This is the code from the penguins tutorial
This is a super basic intro.
Note that there are five types of callouts, including: note, tip, warning, caution, and important.
This is an example of a callout with a caption.
BAP Out
Quarto enables you to weave together content and executable code into a finished document. To learn more about Quarto see https://quarto.org.

The penguins data from the palmerpenguins package contains size measurements for 344 penguins from three species observed on three islands in the Palmer Archipelago, Antarctica.
The plot below shows the relationship between flipper and bill lengths of these penguins.
ggplot(penguins,
aes(x = flipper_length_mm, y = bill_length_mm)) +
geom_point(aes(color = species, shape = species)) +
scale_color_manual(values = c("darkorange","purple","cyan4")) +
labs(
title = "Flipper and bill length",
subtitle = "Dimensions for penguins at Palmer Station LTER",
x = "Flipper length (mm)", y = "Bill length (mm)",
color = "Penguin species", shape = "Penguin species"
) +
theme_minimal()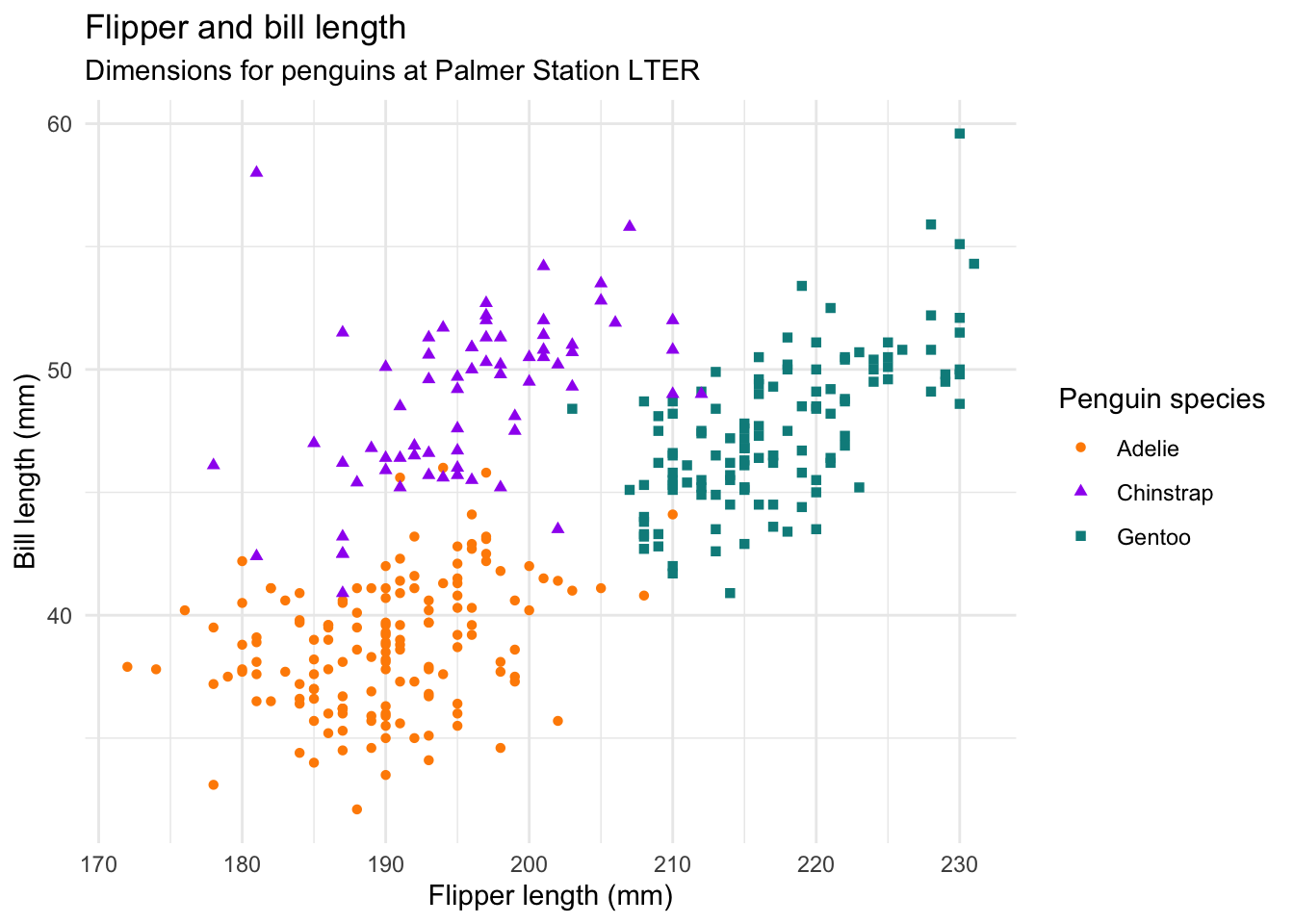
This is the code from the computations
This dataset contains a subset of the fuel economy data from the EPA. Specifically, we use the mpg dataset from the ggplot2 package.
The visualization below shows a positive, strong, and linear relationship between the city and highway mileage of these cars. Additionally, mileage is higher for cars with fewer cylinders.
ggplot(mpg, aes(x = hwy, y = cty, color = cyl)) +
geom_point(alpha = 0.5, size = 2) +
scale_color_viridis_c() +
theme_minimal()
There are 234 observations in our data.
The average city mileage of the cars in our data is 16.86 and the average highway mileage is 23.44.
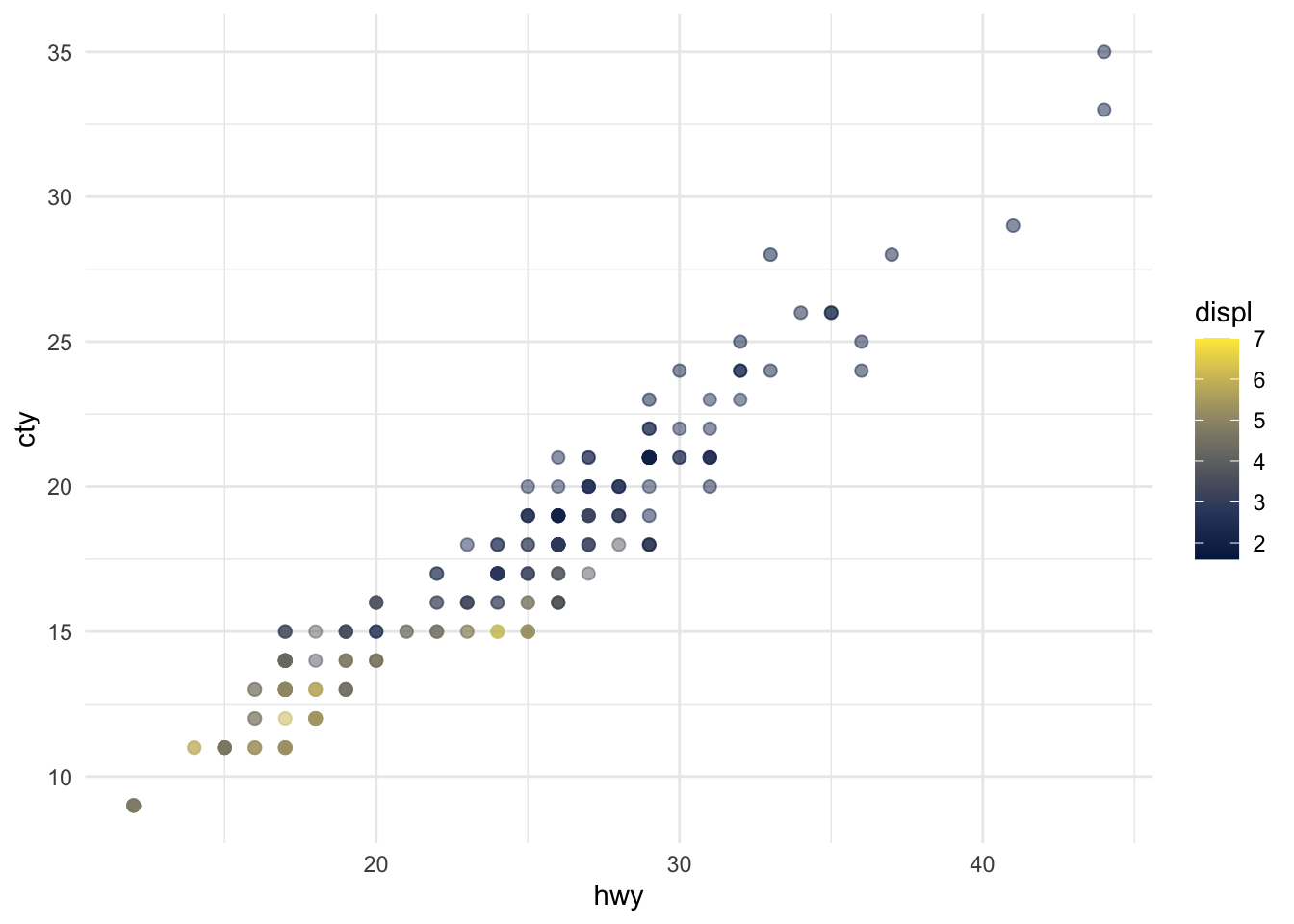
The plots in Figure Figure 1 show the relationship between city and highway mileage for 38 popular models of cars. In Figure Figure 1 (a) the points are colored by the number of cylinders while in Figure Figure 1 (b) the points are colored by engine displacement.
ggplot(mpg, aes(x = hwy, y = cty, color = cyl)) +
geom_point(alpha = 0.5, size = 2) +
scale_color_viridis_c() +
theme_minimal()
ggplot(mpg, aes(x = hwy, y = cty, color = displ)) +
geom_point(alpha = 0.5, size = 2) +
scale_color_viridis_c(option = "E") +
theme_minimal()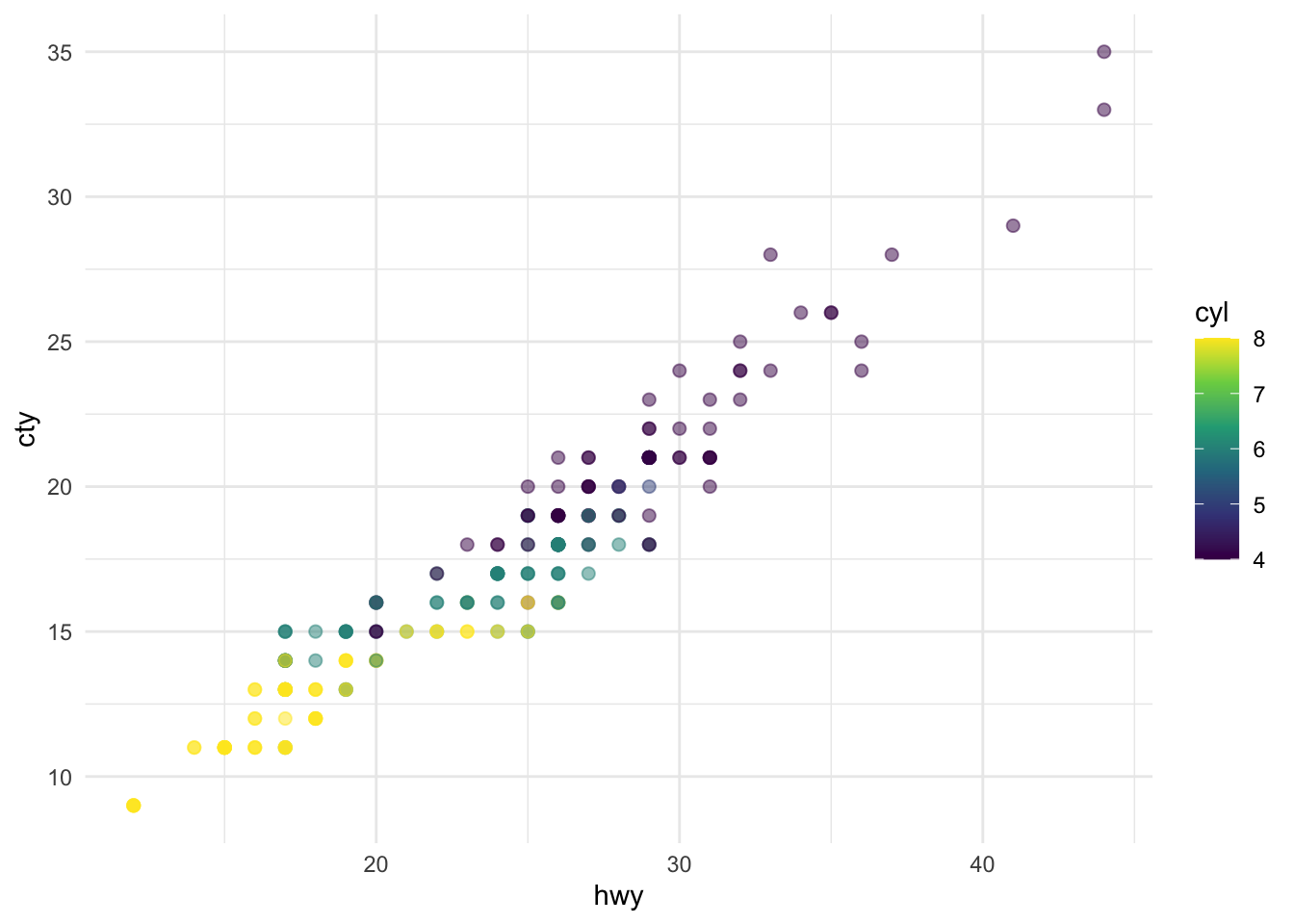
In this analysis, Authoring using housing prices, we build a model predicting sale prices of houses based on data on houses that were sold in the Duke Forest neighborhood of Durham, NC around November 2020. Let’s start by loading the packages we’ll use for the analysis.
We present the results of exploratory data analysis in Section 3.2 and the regression model in Section 3.3.
We’re going to do this analysis using literate programming [@knuth1984].
The data contains 98 houses. As part of the exploratory analysis let’s visualize and summarize the relationship between areas and prices of these houses.
Figure 2 shows two histograms displaying the distributions of price and area individually.
ggplot(duke_forest, aes(x = price)) +
geom_histogram(binwidth = 50000) +
labs(title = "Histogram of prices")
ggplot(duke_forest, aes(x = area)) +
geom_histogram(binwidth = 250) +
labs(title = "Histogram of areas")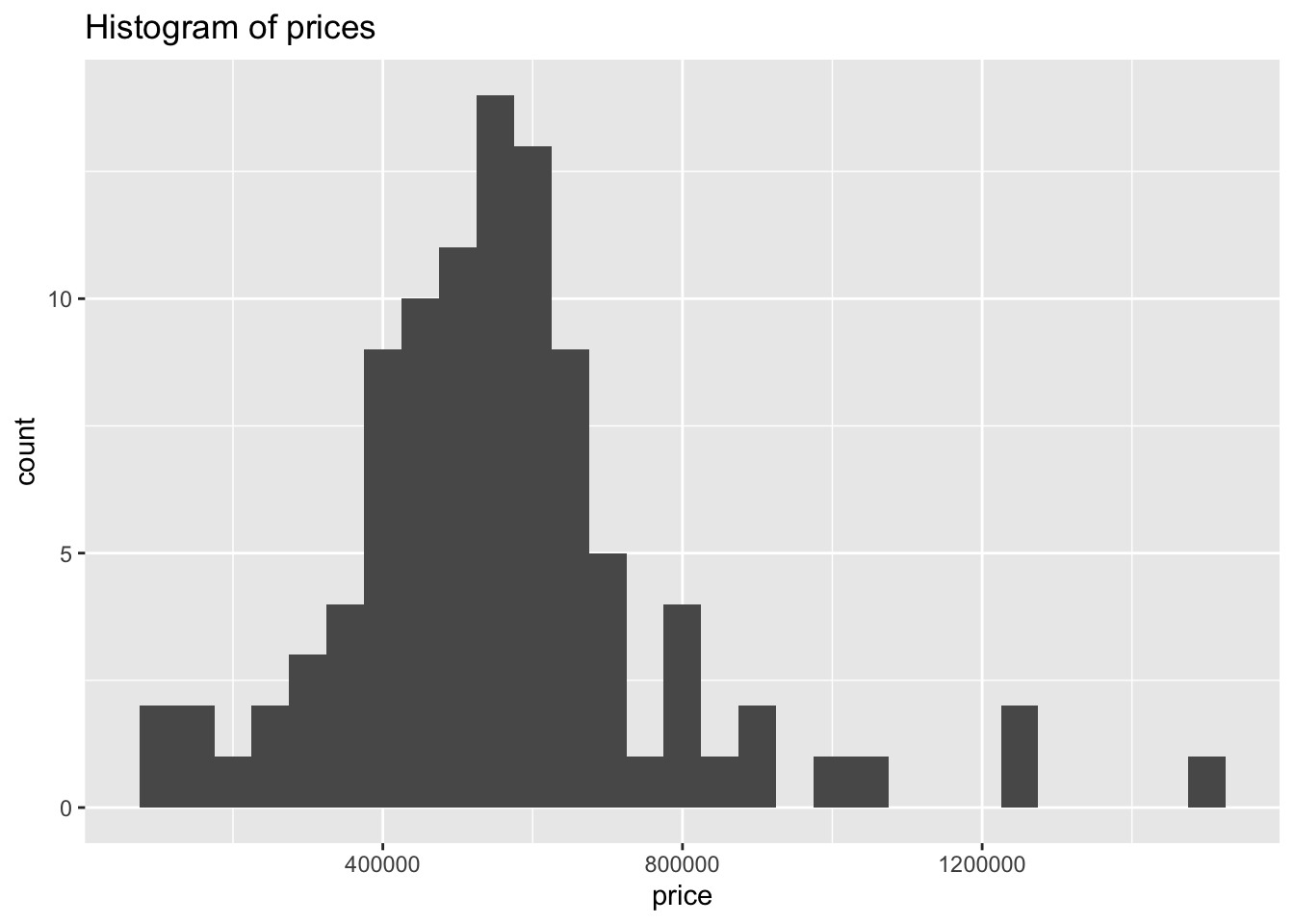
prices
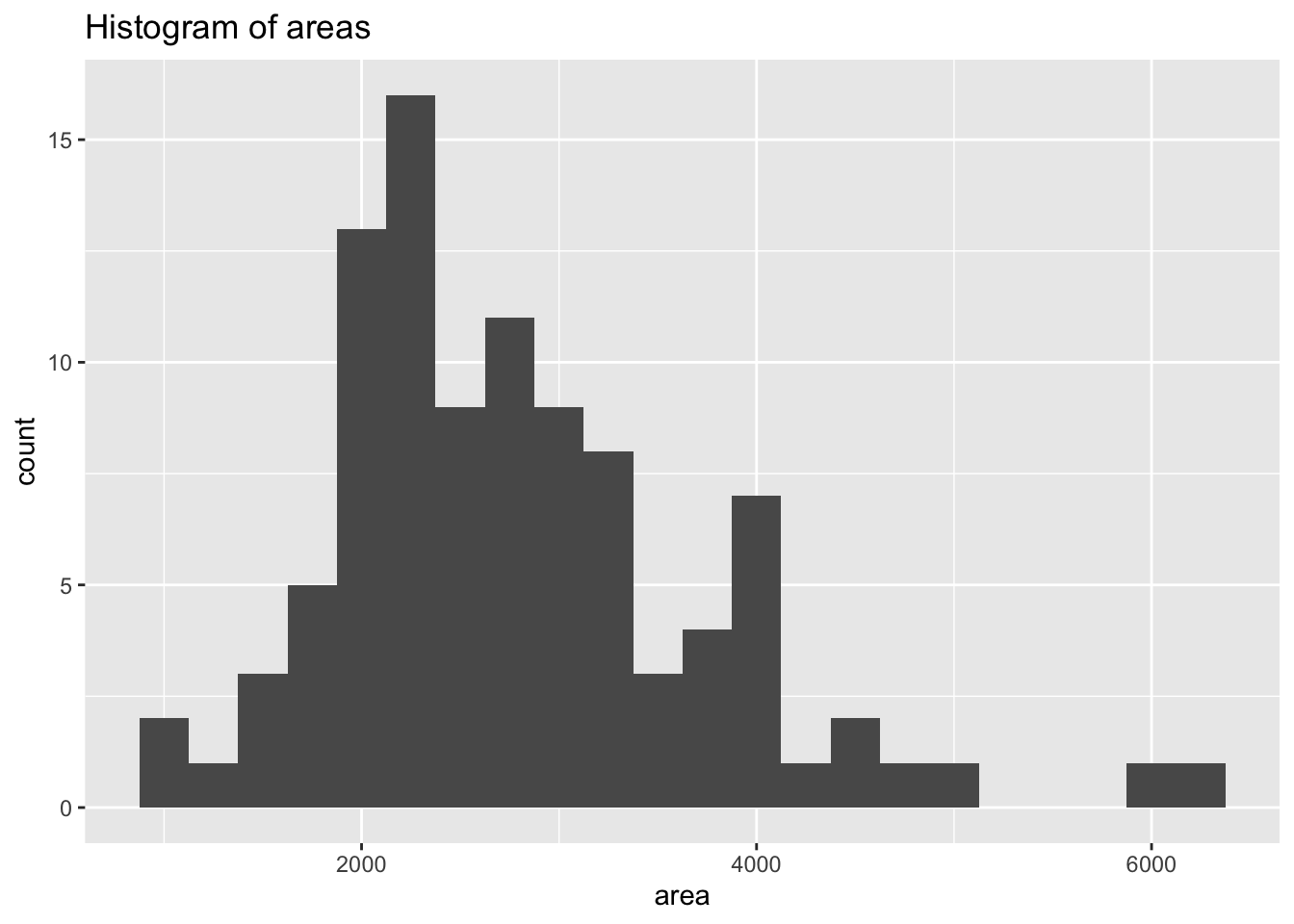
areas
Figure 3 displays the relationship between these two variables in a scatterplot.
ggplot(duke_forest, aes(x = area, y = price)) +
geom_point() +
labs(title = "Price and area of houses in Duke Forest")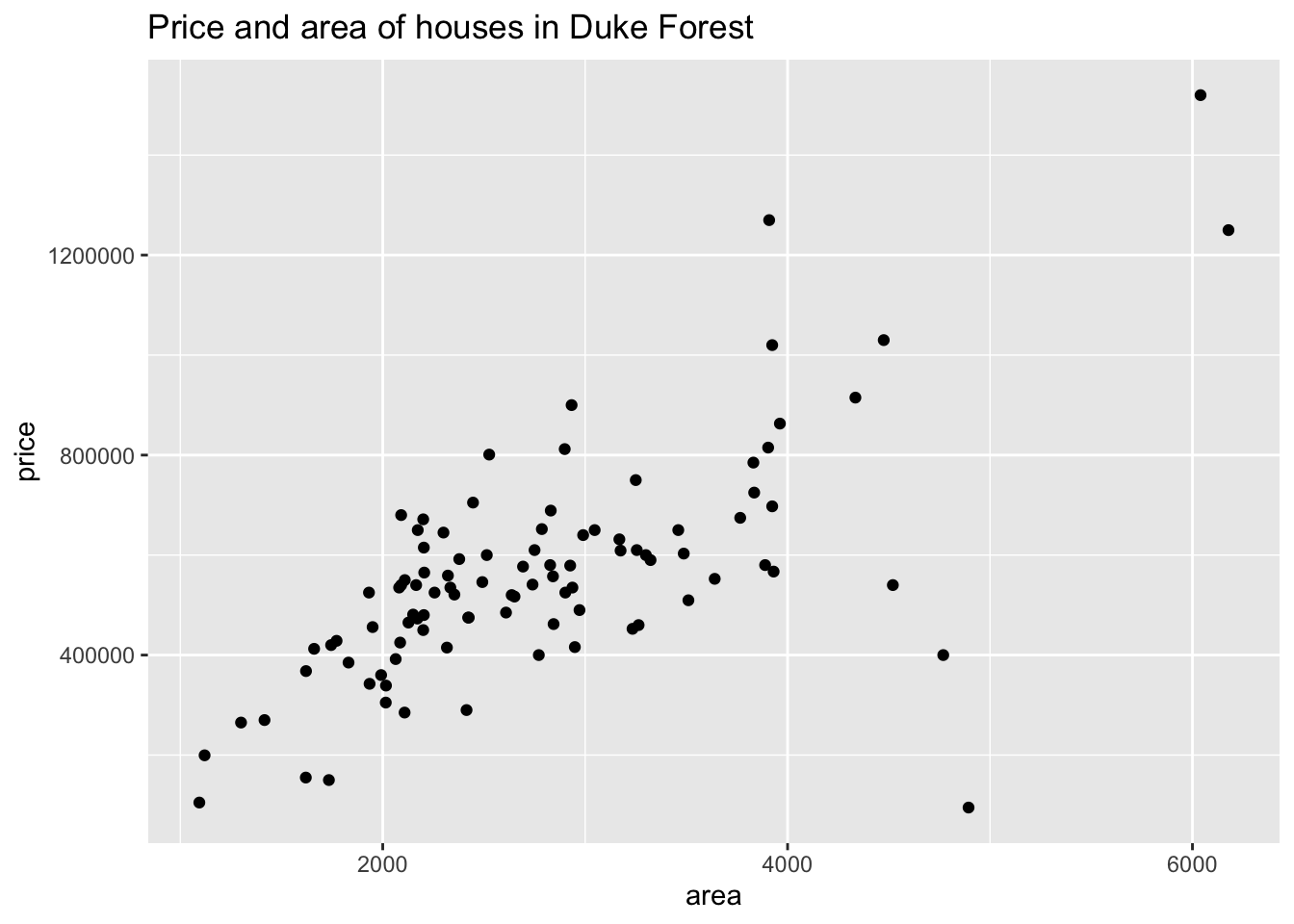
Table 1 displays basic summary statistics for these two variables.
| Median price | IQR price | Median area | IQR area | Correlation, r |
|---|---|---|---|---|
| 540000 | 193125 | 2623 | 1121 | 0.67 |
We can fit a simple linear regression model of the form shown in Equation 1.
price = \hat{\beta}_0 + \hat{\beta}_1 \times area + \epsilon \tag{1}
Table 2 shows the regression output for this model.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 116652 | 53302.46 | 2.19 | 0.03 |
| area | 159 | 18.17 | 8.78 | 0.00 |
This is a pretty incomplete analysis, but hopefully the document provides a good overview of some of the authoring features of Quarto!
@online{bresler2022,
author = {Bresler, Alex and Bresler, Alex},
title = {Quarto {Tutorials}},
date = {2022-05-20},
url = {https://basedmusings.com/posts/2022-05-20-qmd-get-started/},
langid = {en}
}